Bar Graphs vs Histograms
What is the difference between a bar graph and a histogram?
Bar graphs and histograms are both visualizations of data, but they visualize different types of data. Bar graphs are used for categorical variables, while histograms are used for quantitative, usually continuous, variables.
Bar graphs
Bar graphs represent distributions of categorical variables.
A categorical variable is one in which possible values represent membership in a group or category (hence the name categorical). Categorical variables have a limited number of possibilities. If they are coded with numbers, the numbers are arbitrary. For instance, a researcher can decide that the category USA will be coded as 0 or coded as 800 - the number itself typically doesn’t convey any information beyond a label for data analysis purposes.
Some examples of categorical variables include:
Religious affiliation
Gender identification
Cell phone carriers
Dog breeds
Country of citizenship
Bar graphs visually depict the number of observations that fall within each category of a categorical variable.
For example, the bar graph below depicts the distribution of the variable movie Genre. Note that in a bar graph, the order of the categories can be moved around and the graph’s interpretation will not change. Note also that the height of the bar indicates the frequency of the category in the data set.

But what if you have a variable that isn’t measured in groups or categories? For that type of data, we need to use a histogram.
Histograms
Note: much of this description can also be found in the help article on histogram bins.
A histogram is a distribution of a quantitative, and often continuous, variable. A histogram divides the observations of the quantitative variable into intervals and displays these data visually.
A quantitative variable is one in which the variable is measured numerically, and the numbers are meaningful (e.g. height). A continuous variable is one in which there are infinite possible values.
Examples of continuous variables include:
Miles per gallon
Weights of baby elephants in pounds
Average life expectancies in years
Because histograms usually display continuous quantitative variables, and continuous variables can take on almost any value (e.g. 58.1 miles per gallon, 234.6 pounds, 87.0 years), we find it easier to visualize if we group similar values into bins. To create bins, R divides the entire range of the variable’s values into intervals, usually of equal size (e.g. the range of all possible birth weights divided into 20 smaller intervals). One interval is called a bin.
And what goes into each bin? All of the observations that have values within the interval, or bin. The entire area of the rectangle above the bin represents the frequency of the interval values.
For example, to determine what goes into a bin that ranges from 200 - 204.9 pounds, count how many baby elephants in the data weigh between 200 and 204.9 pounds. Each of these observations gets put into the same bin, even though they are not identical values.
These two features - the bin width and the number of values in each bin - together create the basic visual features of the histogram.
Another example: this histogram shows the distribution of Fiber in some common cereals.
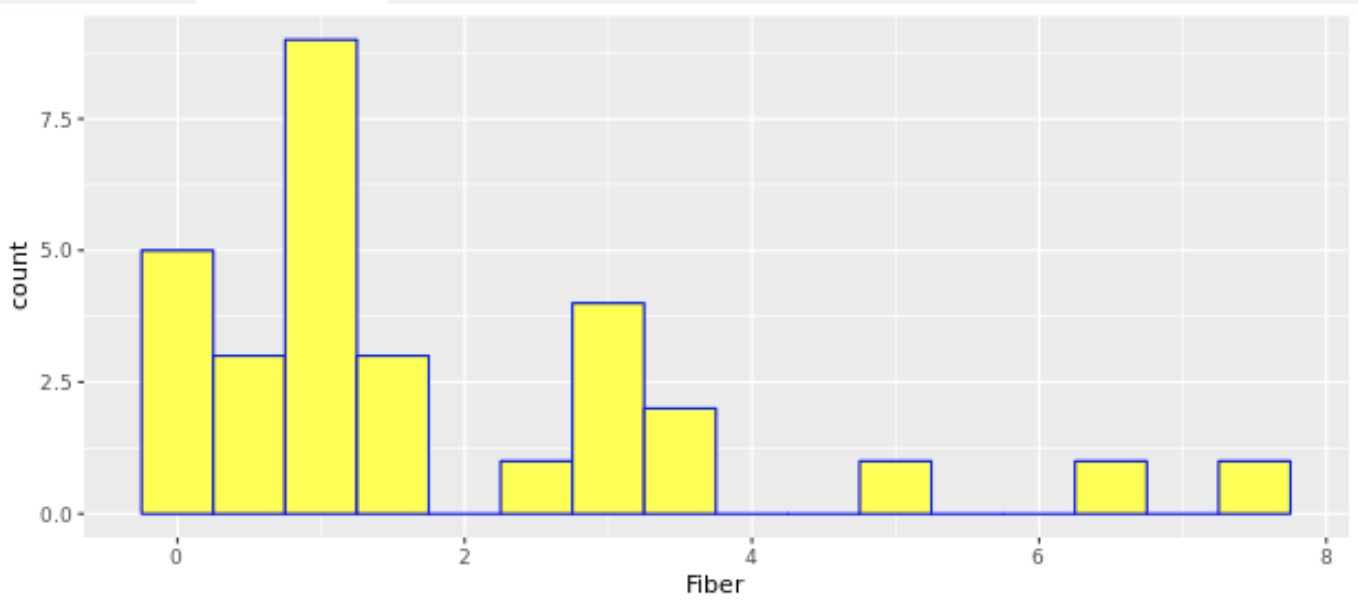
Note that in a histogram, it would be inappropriate to move around the order of the bins, because they are sequential.
Both the bar graph and the histogram each display only one variable. The y-axis is a measure of frequency, that is, how many observations are grouped at each level of the x-axis.
Related Articles
gf_bar()
The gf_bar() function creates a bar graph. It can be used to visualize the distribution of a categorical variable by counting the number of observations for each group of the category. Bar graphs can also be used with the gf_facet_grid() function. ...Faceted Plots
Faceted plots are meant for use when you have a categorical variable. You can use the categorical variable to partition the data into different groups and the groups are then plotted in different panels called facets. Thus, you can use a facet grid ...Quantitative Variables
A quantitative variable is a variable that measures a numerical amount or quantity. Quantitative variables answer questions like “how much?” or “how many?” Examples of Quantitative Variables Variable Example Values Height 62 inches, 70 inches Age 14 ...Categorical Variable
A categorical variable is a variable that places observations into groups or categories. Instead of measuring “how much,” categorical variables describe “which kind.” Examples of Categorical Variables Variable Example Categories Eye color blue, ...Random Sampling
Random sampling is a method of selecting observations in which each member of a population has a known chance of being included in the sample. Random sampling helps create samples that are representative of the population and reduces the risk of ...